ARM汇编学习一
参考资料:ARM汇编语言官方手册.pdf
1. ARM汇编常见指令
1.1 数据处理指令
Ⅰ MOV
- 数据赋值指令;
- mov r0, #0
- 将 立即数 0 加载到寄存器
r0中,也就是给r0赋值为0;
Ⅱ ADD
- 加法指令;
- add r0, r0, r1
- 将 r0 + r1的值赋值给 r0;
Ⅲ SUB
- 减法指令;
- sub r0, r0, r1
- 将 r0 - r1 的值赋值给r0;
Ⅳ AND
- 与操作指令;
- and r0, r0, #6
- 先给r0赋值为5,然后将r0与一个立即数按位与操作,并将结果给r0,这里也可以与另一个寄存器操作;
Ⅴ ORR
- 或操作指令;
- orr r0, r0, #6
- 将r0寄存器的值与6进行或操作,将结果写入r0寄存器中;
Ⅵ EOR
- 异或操作指令;
- eor r0, r0, #8
- 将r0寄存器的值与8进行异或操作,并将结果写入r0寄存器中;
Ⅶ BIC
- 数据位清0指令;
- bic r0, r0, #0xF0000000
- 将
R0的高4位清零,保留低28位;假设想要将后两位置0,则写3,也就是0011,其他的以此类推;
1.2 移位指令
Ⅰ LSL
- 数据左移指令;
- lsl r0, r0, #2
- 左移
n位等价于乘以2的n次方,例如,LSL R0, R0, #2等同于R0 = R0 * 4;
@ 快速乘法运算
MOV R1, #5 @ R1 = 5
LSL R0, R1, #2 @ R0 = 5 << 2 = 20(等价于5×4)Ⅱ LSR
- 数据右移指令;
- lsr r0, r0, #1
- 立即数范围为 0–31(32位寄存器)或 0–63(64位寄存器),右移
n位等价于无符号数除以2的n次方; - 例如,
LSR R0, R1, #2等同于R0 = R1 / 4;
@ 快速无符号除法
MOV R1, #60 @ R1 = 60(二进制111100)
LSR R0, R1, #2 @ R0 = 60 >> 2 = 15(二进制001111)[5](@ref)Ⅲ ROR
- 循环右移指令;并且这里没有循环左移的指令;
- ror r0, r0, #1
- 将寄存器
R0中的二进制数据向右移动 1 位,并将最低位移出的位填充到最高位,形成循环移位;
ROR R0, R0, #1 @ R0 = R0 循环右移1位
@右移时,寄存器中的每一位向右移动指定位数,最低位移出的位依次填充到最高位
MOV R0, #0x12345678 @ R0 = 0001 0010 0011 0100 0101 0110 0111 1000
ROR R0, R0, #8 @ R0 = 0111 1000 0001 0010 0011 0100 0101 0110(即 0x78123456)- ror与lsr有什么区别?
@ LSR(逻辑右移):
@ 将寄存器中的二进制数据向右移动指定位数,左侧空出的高位补0,右侧移出的低位直接丢弃
LSR R0, R1, #3 @ R1右移3位(如R1=0b1000,结果R0=0b0001)
@ ROR(循环右移):
@ 将寄存器中的二进制数据向右移动指定位数,右侧移出的低位依次填充到左侧高位,形成循环移位
ROR R0, R1, #1 @ R1循环右移1位(如R1=0b1010,结果R0=0b0101)
@ LSR 和 ROR 是ARM汇编中两种互补的移位指令:
@ 选择 LSR:当需要无符号除法、数据对齐或清除高位时
@ 选择 ROR:当需要保留所有位(如加密、循环缓冲区)或复杂位操作时Ⅳ ASR
- 算数右移指令;将寄存器中的二进制数据向右移动指定位数,高位填充符号位(正数补0,负数补1),低位移出并丢弃;
- asr r0, r1, #2
- 将
R1的值算术右移2位,结果存入R0(如R1=-8,结果R0=-2);
@ 特性 符号保留 高位填充符号位,确保有符号数的正确性(如负数右移后仍为负数)1.3 乘法指令
Ⅰ MUL
- 乘法指令;不能与常数进行计算;该指令的语法要求所有操作数必须是寄存器,而非直接数值;
- mul r0, r0, r1
- 将r0寄存器的值与r1寄存器的值进行相乘,并将结果放入r0寄存器中;
@ 数据类型:操作数默认视为 无符号整数(若需有符号乘法,需使用 SMULL 指令)
@ 结果范围:结果为 32 位整数,若乘积超过 32 位,高位会被丢弃
@ 目标寄存器(如 R0)和源寄存器(如 R0、R1)必须为 通用寄存器(R0-R12)
@ 目标寄存器不能与第一个源寄存器相同(例如 MUL R0, R0, R0 非法) 需通过临时寄存器实现Ⅱ MLA
- 乘加指令;
- mla r0, r1, r2, r3
- 将两个寄存器的值相乘,再将乘积与第三个寄存器的值相加,最终将结果存入目标寄存器;
MLA R0, R1, R2, R3 @ R0 = R1×R2 + R3
@ 目标寄存器(Rd) 和 乘数寄存器(Rm、Rs)必须为通用寄存器(R0-R12)
@ 目标寄存器不能与第一个乘数寄存器(Rm)相同,例如 MLA R0, R0, R1, R2 非法,需通过临时寄存器中转
@ 但是貌似也正常执行了1.4 内存读写指令
Ⅰ LDR
- 内存读取指令;将内存中的 字数据(32位) 加载到目标寄存器,支持灵活的寻址方式;
- ldr r0, [r1]
- 从 R1 指向的地址加载数据到 R0,这里是将r1存储的地址的值给到r0,不是将地址给r0;
@ LDR 的寻址模式灵活,覆盖多种内存访问需求
@ 基址寻址:
LDR R0, [R1] @ 从 R1 指向的地址加载数据到 R0
@ 基址 + 偏移:
LDR R0, [R1, #8] @ 地址 = R1 + 8(偏移为立即数)
LDR R0, [R1, R2] @ 地址 = R1 + R2(偏移为寄存器值)
@ 前变址寻址(更新基址):
LDR R0, [R1, #8]! @ 地址 = R1 + 8,并更新 R1 为 R1 + 8
@ 后变址寻址(操作后更新基址):
LDR R0, [R1], #8 @ 地址 = R1,操作后 R1 = R1 + 8
@ 寄存器偏移(支持移位):
LDR R0, [R1, R2, LSL #2] @ 地址 = R1 + R2 × 4(左移2位)
@ 标号寻址(相对 PC 的地址):
LDR R0, Label @ 加载 Label 处的数据到 R0(Label 需在 ±4KB 范围内)
``` [3,6,8](@ref)Ⅱ STR
- 内存写入指令,将寄存器中的值存储到内存中,是ARM汇编中核心的数据传输指令之一;
- str r1, [r2]
- 将r1寄存器的地址的值存储到r2中;
STR R1, [R2] @ 将R1的值存入R2指向的内存地址(32位)
STRB R0, [R3, #4] @ 将R0的低8位存入R3+4的地址,并更新R3为R3+4[6,8](@ref)
@ STR 支持多种寻址方式,灵活适应不同场景的内存操作
@ 基址寻址:
STR R0, [R1] @ 地址 = R1
@ 基址+偏移:
STR R0, [R1, #8] @ 地址 = R1 + 8(偏移量可为立即数或寄存器)[6,8](@ref)
@ 前索引寻址:
STR R0, [R1, #8]! @ 地址 = R1 + 8,且R1更新为R1+8[6](@ref)
@ 后索引寻址:
STR R0, [R1], #8 @ 地址 = R1,操作后R1 = R1 +8[6](@ref)
@ 寄存器偏移:
STR R0, [R1, R2, LSL #2] @ 地址 = R1 + (R2 << 2)(用于数组元素访问)[6](@ref)- 是可以选size的,比如 STRB 代表一个字节,还有H或者缺省,分别是16位和32位;也就是两个字节和4个字节;
1.5 跳转指令
Ⅰ B
- 普通跳转指令;
- ARM 汇编中的 无条件/条件跳转指令,用于将程序流程跳转到指定的目标地址继续执行。其核心功能是 改变程序计数器(PC)的值,实现代码分支控制,默认无条件跳转;
Ⅱ BL
- 带链接的跳转指令;意思就是会携带当前指令的下一条指令,以便执行完目标之后继续执行应该执行的下一条指令,可以理解为函数调用;
核心功能包括:
- 跳转执行:将程序计数器(PC)指向目标地址(子程序入口),实现函数调用;
- 保存返回地址:跳转前将下一条指令的地址(
PC + 4)存入链接寄存器 LR(R14),以便子程序结束后返回到调用点;
BL delay @ 调用延时函数,返回地址自动存入 LR
... @ 后续代码
delay:
... @ 子程序逻辑
BX LR @ 返回调用点Ⅲ BX
- 带状态切换的跳转指令;
Ⅳ BLX
- 带链接、带状态切换的跳转指令;
- 支持跳转时切换 ARM/Thumb 指令集状态(根据目标地址最低位判断);
- mov pc,LR:直接修改pc指针,也可以实现跳转;
- LDR PC , 0X???:也是直接修改pc指针,也可以实现跳转;
1.6 数据加载与存储指令
Ⅰ PUSH
- 压栈指令;写入站数据,也可叫做入栈;
PUSH是 ARM 汇编中用于将 寄存器值压入栈 的核心指令,主要功能包括:- 保存寄存器现场:在函数调用或中断处理前,将寄存器的值暂存到栈中,避免数据被覆盖;
- 管理内存结构:利用栈的 后进先出(LIFO) 特性,临时存储数据(如局部变量、参数传递);
- 调整栈指针:压栈后自动更新栈指针(
SP)的值(如SP = SP - 4或SP = SP - 寄存器数量×4);
func:
PUSH {R4-R6, LR} @ 保存寄存器及返回地址到栈中[3,7](@ref)
... @ 函数逻辑
POP {R4-R6, PC} @ 恢复寄存器并跳转回调用点Ⅱ POP
- 出栈指令;弹出栈数据;
func:
PUSH {R4-R6, LR} @ 保存寄存器及返回地址到栈中[3,7](@ref) 从右至左
... @ 函数逻辑
POP {R4-R6, PC} @ 恢复寄存器并跳转回调用点Ⅲ LDM
- 连续读取数据指令;
LDM(Load Multiple)是 ARM 汇编中的 批量加载指令,用于从内存中连续加载多个寄存器的值。其核心功能包括:- 批量数据加载:从指定内存地址开始,依次将数据加载到寄存器列表中;
- 地址自动更新:根据寻址模式自动调整基址寄存器的值(通过后缀
!实现); - 支持堆栈操作:可模拟栈的压入(
POP)和弹出(PUSH)行为,配合STM实现函数调用时的现场保护;
@ LDM{条件码}{模式} Rn{!}, {寄存器列表}{^}
@ 使用 IA 模式(后递增)
STMIA R0!, {R1, R2} @ 将 R1 和 R2 的值依次存入 R0 指向的地址,存储后 R0 += 8
LDMIA R0!, {R3, R4} @ 从 R0 指向的地址依次加载数据到 R3 和 R4,加载后 R0 += 8
@ 使用 DB 模式(前递减)
STMDB R0!, {R1, R2} @ 先 R0 -= 8,再将 R1 存入 [R0],R2 存入 [R0+4]
LDMDB R0!, {R3, R4} @ 先 R0 -= 8,再从 [R0] 加载到 R3,[R0+4] 加载到 R4Ⅳ STM
- 连续写入数据指令;
STM(Store Multiple)是 ARM 汇编中的 批量存储指令,用于将多个寄存器的值批量写入内存。其核心功能包括:- 批量数据存储:将寄存器列表中的值依次存储到连续的内存地址;
- 地址自动更新:根据寻址模式自动调整基址寄存器的值(通过
!后缀实现); - 堆栈操作支持:与
LDM配合使用,实现函数调用、中断处理等场景的 现场保护 和 内存管理;
- 语法与寻址模式:
@ STM{条件码}{模式} Rn{!}, {寄存器列表}{^}
STMIA R0!, {R1, R2} @ 将 R1、R2 存入 R0 起始地址,完成后 R0 += 8
STMFD SP!, {R0-R3, LR} @ 将 R0-R3 和 LR 压入满递减栈(类似 PUSH)2. ARM寻址方式
Ⅰ立即数寻址
- 定义:操作数直接包含在指令中,以
#符号标识,称为 立即数;
ADD R0, R0, #1 @ R0 = R0 + 1(操作数1是立即数)
MOV R1, #0xFF000 @ R1 = 0xFF000(16进制立即数)Ⅱ 寄存器寻址
- 定义:操作数存储在寄存器中,指令直接通过寄存器编号访问;
ADD R3, R1, R2 @ R3 = R1 + R2(操作数均为寄存器)
MOV R4, R5 @ R4 = R5Ⅲ 寄存器间接寻址
- 定义:寄存器中存储的是操作数的 内存地址,需通过
[ ]访问该地址对应的数据;
LDR R0, [R1] @ R0 = 内存地址R1处的值
STR R2, [R3] @ 将R2的值存入R3指向的内存地址- 也可以这么认为:R0 = *R1,相当于取指针;
Ⅳ 基址变址寻址
- 定义:通过基址寄存器(存储基地址)和偏移量(立即数或寄存器)组合计算有效地址;这个也行需要取地址的;
LDR R0, [R1, #4]! @ R0 = [R1+4],执行后R1 +=4(ARM64示例)[4](@ref)
@ !表示会改变R1的值
LDR R0, [R1], #8 @ R0 = [R1],执行后R1 +=8Ⅴ 多寄存器寻址
- 定义:单条指令批量操作多个寄存器,常用于堆栈操作或数据块拷贝;
STMIA R0!, {R1-R4} @ 将R1-R4依次存入R0起始的地址(R0自动递增)
LDMFD SP!, {R0-R3} @ 从栈顶恢复R0-R3(满递减栈模式)[1,2](@ref)Ⅵ 相对寻址
- 定义:以程序计数器(PC)的当前值为基地址,加上指令中指定的偏移量得到有效地址;
BL NEXT @ 跳转到子程序NEXT(PC + 偏移量)
NEXT:
MOV PC, LR @ 返回主程序
@ 应用:用于函数调用和分支跳转3. ARM体系结构概述
参考:ARM汇编语言官方手册.pdf
- ARM 处理器是典型的 RISC 处理器,因为它们执行的是加载/存储体系结构;只有加载和存储指令才能访问内存,数据处理指令只操作寄存器的内容;
RISC:RISC(精简指令集计算机)是一种微处理器架构,它以执行较少类型的计算机指令为特点,从而实现高速度操作;

3.1 寄存器
ARM 处理器拥有 37 个寄存器,包括31个通用寄存器和6个状态寄存器,这些寄存器按部分重叠组方式加以排列,提供了下列寄存器:
- 30 个 32位通用寄存器;
- 程序计数器 pc;
- 应用程序状态寄存器 (APSR)/(CPSR);
- 保存的程序状态寄存器(SPSR);
Ⅰ 30 个 32位通用寄存器
- 在任一时刻都存在十五个通用寄存器,即 r0、r1... r13、r14,具体取决于当前的处理器模式;
- r13 是堆栈指针 (SP),在 Thumb-2 中,sp 被严格定义为堆栈指针,因此如果使用 r13,则在堆栈操作中用处不大的许多指令会产生不可预测的结果;建议不要将 sp 用作通用寄存器;
- 在用户模式下,r14 被用作链接寄存器 (LR),用于存储调用子例程时的返回地址;如果返回地址存储在堆栈上,则也可将 r14 用作通用寄存器;
Ⅱ 程序计数器 pc
- 程序计数器被当作 r15(或 pc)来加以访问;它在 ARM 状态下以一个字(四字节)为增量,在 Thumb 状态下则按指令的大小执行;跳转指令将目标地址加载到 pc 中,也可以使用数据操作指令来直接加载 PC;例如,若要从子例程返回,可以使用以下指令将链接寄存器复制到 PC 中:
MOV pc,lr- 在执行期间,r15 (pc) 不包含当前执行的指令的地址,在 ARM 状态下,当前执行的指令的地址通常是 pc-8,而在 Thumb 状态下通常是 pc-4;这段话其实就是三级流水的概念,可直接跳转到 3.2 三级流水;
Ⅳ 当前程序状态寄存器 (CPSR)
CPSR 存放下列内容:
- APSR 标记、当前处理器模式、中断禁用标记;
- 后续APSR 标记会提及,条件执行会用到;
3.2 三级流水
- ARM三级流水线是早期ARM处理器(如ARM7系列)采用的一种指令执行机制,它将指令处理分为三个主要阶段:取指(Fetch)、译码(Decode)和执行(Execute);这种设计通过并行处理多条指令的不同阶段来提高处理器的吞吐效率;
- 在三级流水线中,每个时钟周期都有一条新指令进入流水线:取指阶段从内存中读取指令,译码阶段解析指令并准备操作数,执行阶段完成实际运算并将结果写回寄存器;
- 当第一条指令处于执行阶段时,第二条指令正在译码,第三条指令正在被取出,形成流水线式的并行处理;
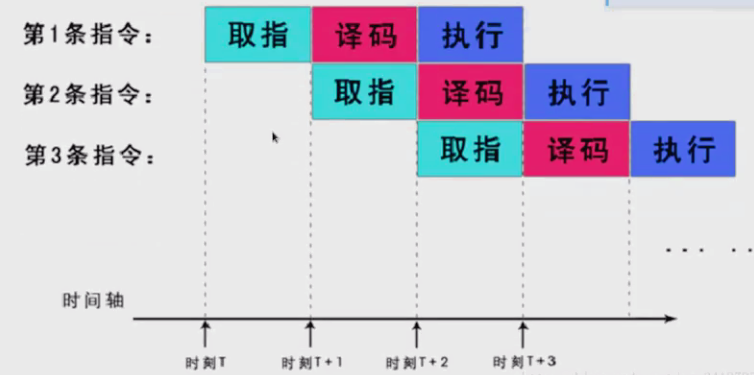
- 形如上图,在执行第一条指令的时候,其实PC已经自动指向了第3条指令,或者说PC总是指向当前指令地址再加2条指令的地址;
处理器处于ARM状态时,每条指令为4个字节,所以PC的值为正在执行的指令地址加2*4=8个字节,即:
- PC值 = 当前程序执行位置 + 8字节
由于三级流水线的并行特性,程序计数器PC总是指向正在取指的指令地址;
- 在ARM状态下(32位指令),这意味着PC=当前执行指令地址+8字节(两条指令的偏移);
- 在Thumb状态下(16位指令)则为PC=当前执行指令地址+4字节。这种偏移是理解ARM汇编编程的关键点之一;
- 反过来说,当前指令的地址则是 pc-8 或者 pc-4 ;
4. 条件执行demo
- 以下示例代码为例子,简单编写汇编程序;
#include <stdio.h>
#include <fcntl.h>
#include <unistd.h>
#include <errno.h>
#include <string.h>
int main(int argc, char *argv[]){
char *num = argv[1];
int int_num = atoi(num); // atoi函数的作用是将字符串转换为整数
if (int_num - 10 > 0)
{
printf("1");
}
else
{
printf("2");
}
return 0;
}- 主要是突出条件执行的写法,因为之前的学习并不足以解决这个需求;先简单编译一个汇编文件,就需要最简单的骨架就好了,直接main函数返回0即可;
clang -target armv7a-linux-androideabi27 -E demo.c -o demo.i
clang -target armv7a-linux-androideabi27 -S demo.i -o demo.s- 会生成一个.s文件,我们就在此基础上写汇编代码;初始代码大概是这样:
main:
.fnstart
movw r0, #0
bx lr- 开始根据需求实现这个小demo,大致汇编代码如下:
main:
.fnstart
push {lr}
sub sp, sp, #8
ldr r0, [r1, #4]
bl atoi
mov r1, #10
cmp r0, r1
movgt r2, #0x31
movle r2, #0x32
str r2, [sp]
@ str sp, [sp, #4]
add r0, sp, #4
mov r0, sp
bl printf
add sp, sp, #8
pop {lr}
movw r0, #0
bx lr- 将其编译成可执行文件再推到设备执行看看是否是想要的效果;
clang -target armv7a-linux-androideabi27 -c demo.s -o demo.o
clang -target armv7a-linux-androideabi27 demo.o -o hello- 得到一个hello文件,推到设备执行;
adb push hello /data/local/tmp/hello
adb shell chmod +x /data/local/tmp/hello
adb shell /data/local/tmp/hello 123- 输出如下:

- 也可以写成一个sh脚本,但是我执行出现了一些问题;
clang -target armv7a-linux-androideabi27 -c demo.s -o demo.o
clang -target armv7a-linux-androideabi27 demo.o -o hello
adb push hello /data/local/tmp/hello
adb shell chmod +x /data/local/tmp/hello
adb shell /data/local/tmp/hello 1235. 调用约定
关于ARM32和ARM64的调用约定大致如下:
- 32:参数传递时,参数0-3放在R0-R3里,超过这个数字就以小端序放在栈上;函数的返回值通常以R0返回,但也有例外;64位的数据可能会使用R0-R1两个寄存器;
- 64:参数传递时,参数0-7放在X0-X7寄存器中,额外的参数以小端序依次放在栈中;函数的返回值通常通过X0返回,大型的数据可能会通过X8寄存器返回;
- 一般来说函数调用时会保存一些寄存器,可以理解为保护现场,在函数结尾又会恢复寄存器,这么做是为了保护上下文;
- 看一个示例:

STMFD SP!, {R11, LR}
MOV R11, SP
SUB SP, SP, #0x38- 这里有三条指令,我们分别来分析一下到底做了什么;
- 先看第一条:
STMFD SP!, {R11, LR}- 首先,STM是多寄存器存储指令,FD则表示指定使用慢递减堆栈类型,一般默认的也是这种类型;这里要注意,堆栈向低地址方向增长,这点对于后面理解比较重要;
{R11, LR}:是要存储的寄存器列表,顺序在 ARM 中通常是固定的,一般是编号低的寄存器存储在低地址;所以这一段具体做的是:将寄存器R11的值存储到新的内存地址,接着存储LR寄存器,最后,将递减后的新地址写回SP寄存器,也就是栈顶; - 注意:这里的感叹号是需要更新寄存器;
- 这里的目的是保存R11和LR寄存器的值,以便执行完成后恢复;因为本函数内部可能还会调用其他函数,是有可能覆盖掉LR寄存器的,所以需要先保存;
- 来看第二条:
MOV R11, SP- 这个指令比较简单,将当前栈指针
SP的值复制到R11寄存器中;它的目的呢?我们来分析一下,此时,SP指向的是刚刚保存完R11和LR后的新栈顶,将此时SP值设置为当前函数的新帧指针 (FP),因为R11是FP;在函数执行过程中,R11将作为一个稳定的基址,用来访问栈帧中的局部变量和参数;也可以说这是栈底; - 再看第三条:
SUB SP, SP, #0x38- 这个指令很简单,从栈指针
SP的当前值中减去十六进制数0x38(即十进制的 56),然后将结果存回SP;它的目的呢?这其实是在为栈开空间,通过减少SP的值(堆栈向低地址增长),“开辟”出了一块从[SP]到[SP + 0x38]的未初始化的内存区域; 这三条指令共同协作,搭建起了函数的“工作台”:
- STMFD SP!, {R11, LR}:保护现场;把“调用者的帧指针”和“回家的地址”安全地存放在栈上;
- MOV R11, SP:建立基地;树立一个稳定的路标(
R11),之后找东西(变量)都以它为基准; - SUB SP, SP, #0x38:开辟工作区;为函数自己的局部变量分配所需的空间;
- 这个例子与调用约定其实关系不大,但也非常值得弄明白;注意堆栈平衡;

